Have you ever spent hours debugging a Sanity CMS project only to discover that invisible characters were breaking your conditional logic? Or found that string comparisons mysteriously fail despite visually identical text? You're not alone. Sanity's Visual Editing features, while powerful, introduce hidden metadata characters that can wreak havoc on your code.
Introduction
Sanity CMS is an exceptional headless content management system that powers websites for companies like Ramp, who recently migrated from Webflow to Sanity for their expanding content needs. However, one particularly frustrating challenge lurks beneath the surface: stega encoding – invisible characters that Sanity embeds in strings to support its Visual Editing features.
These hidden characters cause string comparisons to fail, break conditional rendering, and create maddening bugs that seem impossible to track down. The symptoms are subtle but the impact is severe: components render incorrectly, CSS classes don't apply as expected, and equality checks fail for seemingly identical strings.
Consider this real-world example from a recent project:
// This conditional mysteriously fails despite text appearing identical{pageType === "blog" ? <BlogHeader /> : <StandardHeader />}
Identify when stega encoding is causing issues in your Sanity projects
Properly implement stegaClean to eliminate these hidden characters
Debug string comparison problems with confidence
Create utility functions to handle stega cleaning systematically
Prevent future headaches with best practices for Sanity string handling
Prerequisites
Basic knowledge of Sanity CMS
Experience with Next.js or similar frontend frameworks
Familiarity with JavaScript string operations
A Sanity project with Visual Editing features
Understanding Stega Encoding
What Is Stega Encoding and Why Does It Exist?
Stega encoding (short for steganography encoding) is a technique Sanity uses to embed metadata within text strings. This metadata supports Sanity's Visual Editing features, allowing content creators to see real-time previews and enabling developers to build sophisticated editing experiences.
While this technology powers Sanity's excellent visual editing capabilities, it introduces invisible characters into your strings that can cause unexpected behavior in your frontend code.
The Hidden Characters Lurking in Your Content
These hidden characters include:
ZeroWidthSpace (​ or Unicode U+200B)
Zero Width Joiner (‍ or Unicode U+200D)
Zero Width Non-Joiner (‌ or Unicode U+200C)
Byte Order Mark ( or Unicode U+FEFF)
What makes these characters particularly problematic is that they're invisible in normal text display but are very much present in the string data. This means code that looks correct can behave unexpectedly.
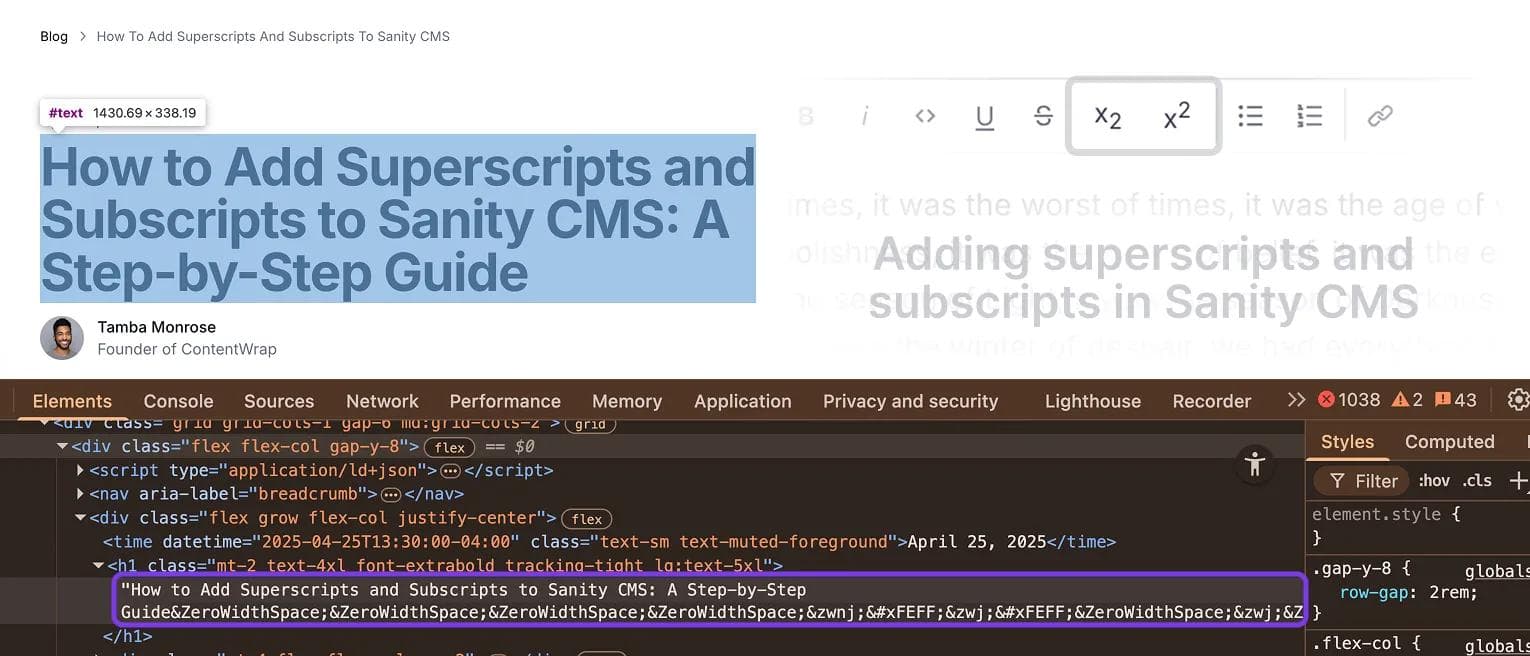
white space and zero width characters appearing in Sanity CMS preview mode
<h1 class="mt-2 text-4xl font-extrabold tracking-tight lg:text-5xl"> How to Add Superscripts and Subscripts to Sanity CMS: A Step-by-Step Guide​​​​‌‍​‍​‍‌‍‌​‍‌[...]</h1>
Notice all those extra character entities after the visible text? Those are stega characters that will break string comparisons and equality checks.
Before and After stegaClean
Here's a comparison of a string value before and after applying stegaClean:
Before:
console.log(title); // Output: "Product Features"// Note: The hidden characters aren't visible in console output but are present
After:
import { stegaClean } from '@sanity/client/stega'console.log(stegaClean(title));// Output: "Product Features"// Clean, without any hidden characters
The Real-World Impact
When Equality Checks Mysteriously Fail
One of the most common issues with stega encoding is equality checks that should work but don't:
// This will often fail despite appearing correctif (category === "Technology") { // This code never executes even when category looks like "Technology"}// The solutionimport { stegaClean } from '@sanity/client/stega'if (stegaClean(category) === "Technology") { // Now this works correctly}
CSS Classes Don't Apply as Expected
Another frequent issue occurs when dynamic class names don't apply:
// Before: Class won't apply due to hidden characters<div className={`card ${type === "featured" ? "card-featured" : ""}`}>// After: stegaClean ensures proper class application<div className={`card ${stegaClean(type) === "featured" ? "card-featured" : ""}`}>
Component Rendering Issues
Conditional rendering often breaks with stega-encoded strings:
// More robust solutionif (stegaClean(value).toLowerCase() === "expected".toLowerCase()) {}
Problem: Missing stegaClean in Nested Objects
Symptoms:
Some comparisons work, others don't
Inconsistent behavior across components
Solution: Use the cleanObject utility we created:
// Beforeconst post = { title: sanityData.title, // Has stega characters description: sanityData.description, // Has stega characters categories: sanityData.categories // Array with stega characters};// Afterimport { cleanObject } from '../utils/sanityHelpers';const post = cleanObject(sanityData);
Problem: Cleaning Values That Don't Need It
Symptoms:
Unnecessary performance overhead
Applying stegaClean to non-Sanity strings
Solution: Only apply stegaClean to strings from Sanity:
// Helper function to determine if cleaning is neededfunction needsCleaning(str) { if (typeof str !== 'string') return false; // Check for common stega characters return /[\u200B\u200C\u200D\uFEFF]/.test(str);}// Optimized cleaning functionfunction smartClean(str) { if (!needsCleaning(str)) return str; return stegaClean(str);}
Problem: stegaClean Missing from Build
Symptoms:
Works in development but fails in production
Import errors
Solution: Ensure proper import path and check bundling:
// Try alternative import paths if neededimport { stegaClean } from '@sanity/client/stega'// orimport { stegaClean } from '@sanity/client/dist/stega'// Create a fallback if neededfunction safeStegaClean(str) { try { return stegaClean(str); } catch (e) { console.warn('stegaClean failed, returning original string', e); return str; }}
Problem: Hidden Characters in URL Slugs
Symptoms:
Broken links
404 errors on seemingly correct URLs
Solution: Always clean slugs:
// In your getStaticPaths or route handlerexport async function getStaticPaths() { const posts = await client.fetch(`*[_type == "post"]{ slug }`); return { paths: posts.map(post => ({ params: { slug: stegaClean(post.slug.current) } })), fallback: false };}
Conclusion and Next Steps
Stega encoding is a necessary component of Sanity's powerful Visual Editing features, but the hidden characters it introduces can cause frustrating bugs in your applications. By systematically implementing stegaClean, you can eliminate these issues while still benefiting from Sanity's excellent editing experience.
Let's recap what we've learned:
Sanity embeds invisible characters like ZeroWidthSpace, ZWJ, ZWNJ, and BOM in strings
These characters break equality checks, conditional rendering, and string operations
stegaClean removes these characters, making strings behave as expected
Implementing stegaClean systematically through utilities and HOCs ensures consistent behavior
Next Steps
To further enhance your Sanity CMS development experience:
Create a stegaClean Linting Rule: Build an ESLint rule to flag potential stega issues
Automate Testing: Add tests specifically for stega character handling
Explore Sanity's Presentation Tool: Learn more about Visual Editing capabilities
Contribute: Share your stegaClean utilities with the Sanity community
How to Implement Text Wrap Around Images in Sanity CMS: A Step-by-Step Guide
Frustrated by Sanity's inability to wrap text around images? This tutorial shows you how to build a custom component that gives your content editors the power to float images left or right with adjustable width controls — just like Webflow.